von Louise Tharandt und Michael Markert
OpenRefine ist ein leistungsstarkes Open-Source-Tool zur Datenbereinigung und -transformation, das im GLAM-Bereich (Galleries, Libraries, Archives, Museums) und in Universitätssammlungen wertvolle Dienste leistet. Gerade hier, wo heterogene und historisch gewachsene Datensätze oft inkonsistente Metadaten aufweisen, hilft OpenRefine.
Das Tool kann:
- praktisch alle Text-Dateiformate und Datenstrukturen wie CSV, XML, JSON importieren
- einen schnellen Überblick über Dateien mit zehntausenden Zeilen schaffen
- Bereinigungs- und Sortieraufgaben durchführen, etwa vor dem Import von Daten in ein neues Dokumentationssystem
- durch Zugriff auf Webseiten und Schnittstellen diese Daten verarbeiten (z. B. für einen Abgleich mit der GND, Wikidata, OpenStreetMap usw.)
- wiederholbare, komplexe Bearbeitungsschritte mit Hilfe der eigenen Skriptsprache GREL durchführen, die ganze Spalten oder die ganze Tabelle betreffen
- bei der Transformation in andere Datenformate (Export) unterstützen
Ob zur Vorbereitung digitaler Sammlungen, für Systemmigrationen oder zur besseren Integration in Forschungsinfrastrukturen – OpenRefine erleichtert die Arbeit mit Metadaten erheblich und trägt dazu bei, Sammlungen besser zu erschließen und nachhaltig nutzbar zu machen.
Die folgenden Anwendungsfälle geben einen Einblick in die Arbeit mit und Nutzung von OpenRefine.
Anwendungsfälle
Schreibweisen vereinheitlichen mit Clustering
Eine der am häufigsten genutzten Funktionen in OpenRefine ist die Vereinheitlichung von Schreibweisen mithilfe der Clustering-Funktion. Besonders in Datensätzen, in denen Bezeichnungen für Teilsammlungen oder Objektnamen oft variieren und historisch gewachsene Daten oft unterschiedliche Schreibweisen aufzeigen, hilft dieses Feature, Inkonsistenzen effizient zu bereinigen.
Durch das Erstellen eines Text Facets und den Einsatz verschiedener Keying Functions – etwa Cologne Phonetic zur phonetischen Gruppierung – lassen sich ähnliche Begriffe identifizieren. Anschließend können falsche oder uneinheitliche Schreibweisen per Merge zusammengeführt und korrigiert werden. Das Clustering erfolgt über den gesamten Inhalt der Spalte und kann gleichzieitg eine hohe Anzahl von Ergebnissen und Vorschlägen liefern, die dadurch nicht einzeln gefunden und bearbeitet werden müssen. So ermöglicht OpenRefine eine präzisere und konsistentere Datenstruktur, was die Qualität und Nachnutzbarkeit der Metadaten erheblich verbessert.
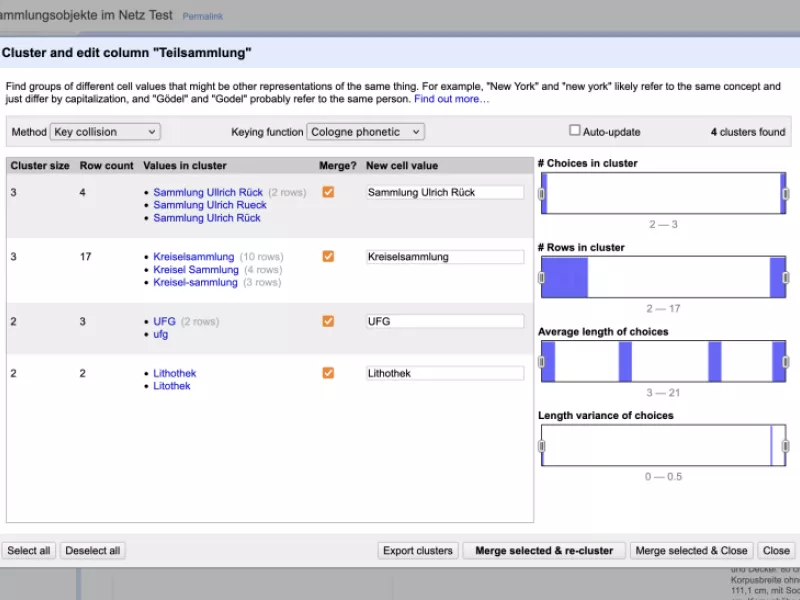
Im gezeigten Fall (Abb. 1) waren unterschiedliche Schreibweisen für Teilsammlungen in dem Datensatz zu sehen. Die gesamte Spalte des Datensatzes wurde geclustert, die Schreibweise der Inhalte wurde verglichen und bei vier Teilsammlungen konnten unterschiedliche Schreibweisen gefunden werden. Die korrekte Schreibweise wurde angegeben und dann automatisch im Datensatz für alle Daten der jeweiligen Teilsammlungen angepasst.
Teilen und Zusammenfügen
Das Teilen und Zusammenführen von Spalten ist eine weitere Funktion in OpenRefine, die besonders bei der Bereinigung und Standardisierung von Metadaten eine wichtige Rolle spielt. In einigen Sammlungen sind Datensätze oft historisch gewachsen und enthalten beispielsweise Namen, Datumsangaben oder Klassifikationen in uneinheitlichen Formaten. Hier hilft OpenRefine, Struktur und Konsistenz in die Daten zu bringen.
Mit der Split-Funktion lassen sich Inhalte einer Spalte anhand von Trennzeichen wie Kommata, Leerzeichen oder Sonderzeichen in mehrere Spalten aufteilen. Dies ist besonders nützlich, wenn etwa Vor- und Nachnamen in einer einzigen Spalte erfasst wurden oder wenn mehrteilige Inventarnummern für eine bessere Systematisierung getrennt werden müssen. Umgekehrt ermöglicht die Join-Funktion das Zusammenführen von Spalteninhalten, beispielsweise um verstreute Datumsangaben oder mehrteilige Bezeichnungen in ein einheitliches Format zu bringen.
Diese Funktionen sind essenziell für die Harmonisierung von Daten und erleichtern die Weiterverarbeitung in digitalen Erfassungsssystemen.
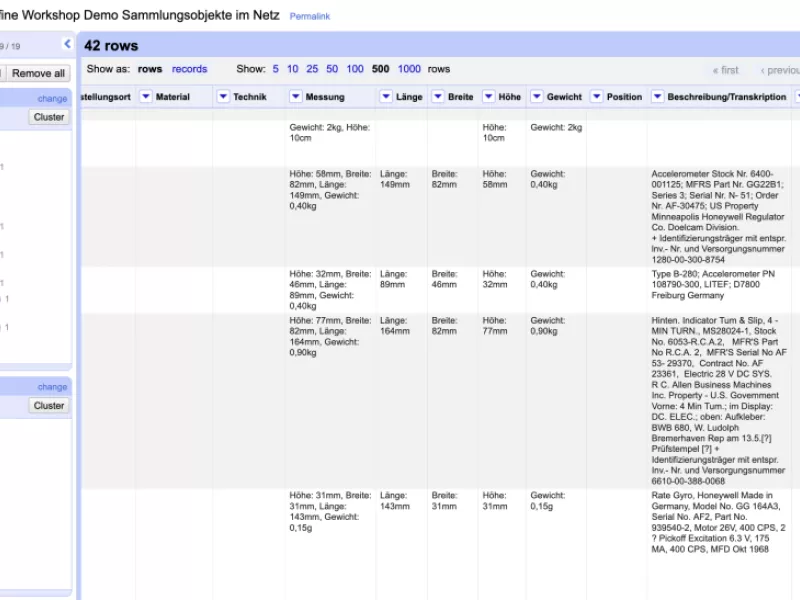
In diesem Beispiel (Abb. 2) wurde eine Spalte, die gesammelt und unsortiert alle Werte zu Länge, Breite, Höhe und Gewicht enthalten hatte, unter Einsatz von GREL (General Refine Expression Language) in vier verschiedene Spalten getrennt, die nun in geordneter Reihenfolge alle Werte getrennt angeben.
Informationen aus dem Internet einbinden
In OpenRefine ist es verhältnismäßig einfach, Informationen aus Webseiten oder Schnittstellen zu extrahieren. Die entsprechenden Werkzeuge zur Verarbeitung hierarchisch strukturierter Zeichenketten wie HTML, JSON oder XML sind direkt eingebaut. Es gibt dazu viele sehr gute Tutorials, wie die Lesson Fetching and Parsing Data from the Web with OpenRefine von Programming Historian.
Sucht man etwa die Koordinaten oder das Bundesland zu einer Postadresse, so kann man direkt aus OpenRefine auf eine Schnittstelle von OpenStreetMap zugreifen und aus deren Antwort (API response) die benötigten Werte herauslesen (parsing). Dazu muss man natürlich wissen, unter welcher Webadresse man die Schnittstelle findet, wie man die Anfrage strukturieren muss und wo genau dann im Ergebnis der gesuchte Wert steht. Eine kurze Anleitung zu Abfrage und Parsing für den Fall Addresssuche findet sich beispielsweise im OpenRefine Forum.
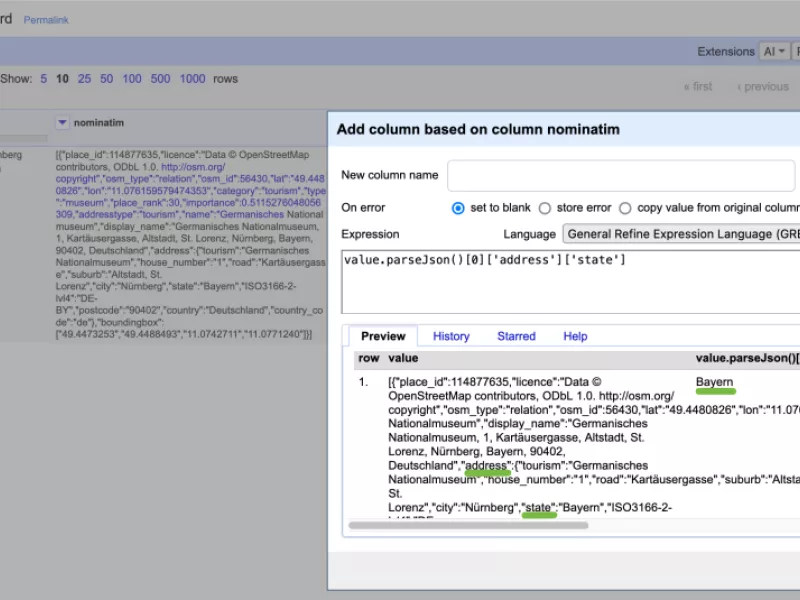
Im Beispiel (Abb. 3) wurde in einem ersten Schritt die Antwort der Schnittstelle in eine neue Spalte geladen. Dann wird der gesuchte Wert für das Bundesland herausgezogen: im OpenStreetMap JSON Schema (OSM JSON) steht der Wert für "state" innerhalb von "address" im ersten und einzigen Treffer der Liste.
Filtern und Exportieren
Besonders praktisch ist an OpenRefine, dass man sich sehr schnell einen Überblick über sehr große Datenpools verschaffen und diese unkompliziert filtern und sortieren kann. OpenRefine erstellt aus Begriffen einer Spalte ebenso Facetten, wie aus Zeitangaben. Die Facetten lassen sich dann beliebig kombinieren und invertieren. So findet man auch schnell falsch geschriebene Termini, fehlende oder unschlüssige Angaben – etwa weil jemand beim Eintragen in der Spalte verrutscht ist.
Die Facetten sind etwa dann hilfreich, wenn nur ein Teil einer großen Datenmenge weitergegeben werden soll – zum Beispiel weil man verschiedene Expert*innen auf verschiedene Teile schauen lassen möchte oder bestimmte Informationen (noch) nicht weitergegeben werden sollen.
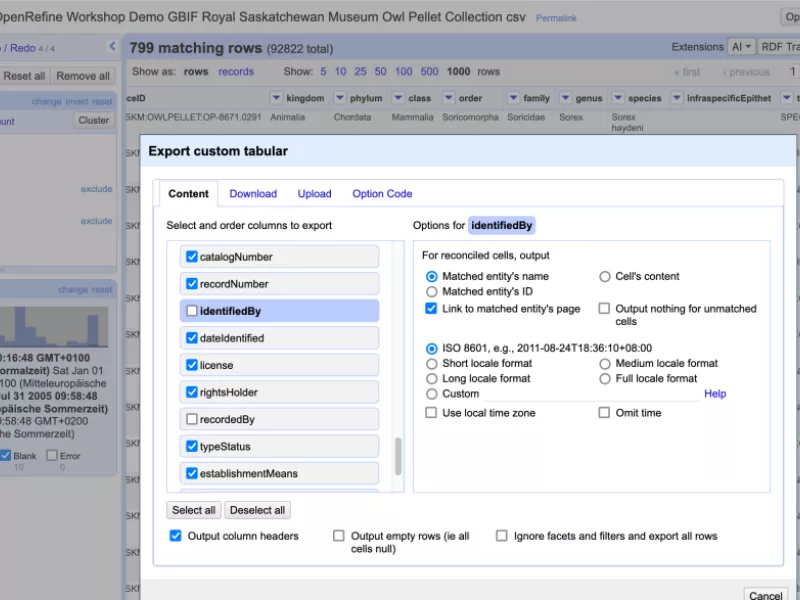
Im obigen Beispiel (Abb. 4.) wurden mittels der Facetten alle Belege von Hasenartigen und Spitzmausartigen ausgewählt, die von 2000 bis 2005 in kanadischen Eulengewöllen gefunden wurden – 799 von 92822 Angaben. Beim Export lassen sich dann die zu exportierenden Spalten auswählen und neu anordnen sowie das Exportformat festlegen.
Wo kann man mehr erfahren?
Der Funktionsumfang von OpenRefine ist natürlich um einiges größer als hier dargestellt. Wir bieten aus SODa heraus daher eine Reihe von Formaten an, um das Werkzeug näher kennenzulernen, auszuprobieren und konkrete Herausforderungen zu diskutieren. Unseren ersten OpenRefine-Einführungsworkshop haben wir am 23. Januar online durchgeführt – er kann zum Selbststudium anhand des erstellten Tutorials nachgenutzt werden.
Den nächsten Workshop veranstalten wir auf unserem SODa-Barcamp (7.-9. April 2025) und werden für Fortgeschrittene bei der Gelegenheit einen weiteren anbieten, der die Arbeit mit Webquellen, den Abgleich mit Wikidata und der GND (Reconciling) sowie andere komplexere Funktionen zum Thema hat. Ab April bieten wir zudem an jedem 4. Donnerstag des Monats eine Sprechstunde zu OpenRefine an – 11 Uhr in geraden und 15 Uhr in ungeraden Monaten. Der erste Termin ist Do., 24.04., 11 Uhr in Zoom: (https://sammlungen.io/join).
Wir würden uns sehr freuen, wenn Ihr mit Euren Fragen und Daten bei dem einen oder anderen Format vorbeischaut und wir gemeinsam mehr darüber lernen können, wie sich OpenRefine in der Sammlungsarbeit einsetzen lässt.