Von Anna Gnyp
Intensiver Austausch auf Augenhöhe, spannende Themen rund um die Bereiche Sammlungen, Objekte und Datenkompetenzen, erkenntnisreiche Sessions – das war das SODa Barcamp 2024! Knapp 60 Barcamper*innen haben sich insgesamt vom 14.–16. Oktober trotz vorgelagertem Berliner Baustellendschungel im Hedwig-Dohm-Haus, in Berlin Mitte, eingefunden, um zu brainstormen und sich über Herausforderungen bei der Sammlungsdigitalisierung auszutauschen.

Zu unserer Freude setzte sich der Teilnehmerkreis aus Personen zusammen, die auf verschiedenen Ebenen mit Sammlungen arbeiten: einerseits Sammlungskoordinator*innen und Forschende, aber auch digitale Sammlungsmanager*innen, Research Software Engineers sowie Kolleg*innen aus anderen Datenkompetenzzentren wie digiS Berlin, WiNoDa und vom Konsortium NFDI4Objects. Die Herausforderung bestand nun darin, die Themenvorstellungen und die Sessions für alle Teilnehmenden, unabhängig ihrer mitgebrachten Datenkompetenzen, verständlich und spannend zu gestalten.
Zur Unterstützung dieser Mission sorgte das SODa-Team nicht nur für die Moderation, sondern auch für das nicht zu vernachlässigende leibliche Wohl.
Die Sessionplanung
Nach dem lockeren Empfang bei Kaffee und Muffins, ging es auch schon los mit einem kleinen Warm-up und der Sessionplanung für die drei Barcamp-Tage. Weil zu Beginn eines Barcamps noch keine Agenda existiert, wurden zunächst Vorschläge von allen Teilnehmer*innen gesammelt. In einem anschließenden Voting kristallisierten sich schließlich Interessenschwerpunkte heraus, die maßgeblich die zeitliche und räumliche Planung der Sessions steuerten. Aus den vorgeschlagenen Themen wurden somit insgesamt 17 Sessions in fünf Zeitblöcken organisiert.

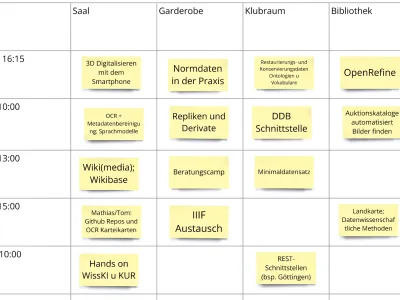
Probieren geht über Studieren

Die Themen der Sessions waren genauso breit gefächert wie die Formate: eine Hands-on-Session in die 3D-Digitalisierung mit dem Smartphone, ein Beratungscamp zur Arbeit mit strukturierten Daten und Einführungen in die Sammlungserschließung mit WissKi, zur Nutzung der Schnittstelle der Deutschen Digitalen Bibliothek sowie zur Datenbearbeitung mit OpenRefine. Im Klubraum wurde angeregt darüber diskutiert, was für Daten bei der Restaurierung und Konservierungsdokumentation anfallen und ob und wie ein Dokumentationsstandard realisierbar ist. Gleichzeitig tauschte man sich in der Garderobe darüber aus, welche Normdaten in der Praxis wirklich genutzt werden und welche Vor- und Nachteile bestimmte Normdatensysteme haben. Und vieles mehr.

KI und OCR-Kompetenz?
Auch das Thema Large Language Models durfte natürlich nicht fehlen. Überraschend für viele Barcamper*innen war vermutlich die Erkenntnis, wie gut ChatGPT handschriftlich ausgefüllte Objektzettel auslesen und in einem maschinenlesbaren Format strukturiert wiedergeben kann. Bei dem Versuch einen Brief in Kurrentschrift zu transkribieren generierte die KI einen auf den ersten Blick plausibel klingenden Text. Durch die Fachexpertise einer Teilnehmerin wurde der Text aber als stark fehlerhaft entlarvt.
Für solche anspruchsvollen Texterkennungs-Projekte wurden in einer weiteren Session energiesparendere und freie OCR-Anwendungen wie „OCR4all“ und „Pero-ocr“ empfohlen und ausprobiert.

Von A wie Auktionskataloge bis W wie Wikidata
Ein weiteres Themenfeld aus dem KI-Bereich waren Tools zum Erkennen von Bildähnlichkeiten und Objekten auf Bildern. Auch hier durften die Barcamper*innen selbst Hand anlegen und unter Anleitung mittels der Programmiersprache Python ein Objekterkennungstool mit Bildern von Auktionskatalogen trainieren und erproben. Im Fazit sahen die Teilnehmer*innen noch Optimierungsbedarf, da die Ergebnisse gut, aber die Trefferquote noch unzureichend ist. Potenzial für den Einsatz in der Provenienzforschung hätte die Anwendung aber schon, wenn es mehr Bilder zum Abgleich gäbe.
In einer Session über das Zusammenspiel von Wikimedia-Projekten und Sammlungen gab es eine kurze Einführung in die freie und kollaborative Datenbank Wikidata und die Bilddatenbank Wikimedia Commons. Beispiele veranschaulichten wie Museen, Sammlungen sowie Forschende diese Dienste nutzen.

Eine interessante Diskussion entfachte sich vor allem darüber, in welchen Fällen eine Datenpublikation in Wikidata, FactGrid, einer speziell für Historiker*innen aufgesetzten und restriktiveren Wikibase-Instanz, oder in einer eigenen Wikibase Sinn macht. Philosophischer wurde es dann bei der Diskussion, ob die Modellierung der CIDOC-CRM Ontologie in einer eigenen Wikibase-Instanz im Grunde ein ähnliches Datenbanksystem wie Wisski darstellen würde. In jedem Fall bot die Session viel Futter zum Weiterdenken...
Nach dem Barcamp ist vor dem Barcamp
Neben den tollen Erkenntnissen und Ideen, die aus dem SODa Barcamp resultierten, gab es natürlich noch einen sehr schönen Nebeneffekt: das Networking. Bei knapp 60 Teilnehmenden aus 12 Städten sind viele neue Kontakte und Ideen für gemeinsame Veranstaltungen entstanden.
Für alle, die nicht dabei sein konnten, haben wir versucht, die einzelnen Sessions so gut wie möglich mittels Etherpads zu dokumentieren und im Sessionplan zu hinterlegen. Außerdem werden die Präsentationen, sofern vorhanden, auf Zenodo veröffentlicht. Einige Teilnehmer*innen haben ihre Folien ebenfalls zur Verfügung gestellt, wie z.B. eine Einführung in die DDB-Schnittstelle(n) sowie eine Vorstellung der Minimaldatensatz-Empfehlung für Museen und Sammlungen. Für weitere Fragen und Anregungen zu den Inhalten, kann man uns gerne kontaktieren.

Wir möchten uns bei allen Barcamper*innen bedanken, die mit ihrer Begeisterung, Ideen, Expertise und ihren Fragen unser Barcamp zu einem gelungenen Event gemacht haben! Sehr gefreut haben wir uns auch über eine NFDI4Objects-Delegation und einen Austausch zu Datenmodellen. Wir sehen uns alle nächstes Jahr in Nürnberg!
Hier geht es zur archivierten Veranstaltungsseite mit der Programmübersicht.